
EdgeDb vs. Prisma
This document compares EdgeDB (v2.9) to the Prisma Edge Client and Prisma Serverless Data Proxy.
A type-safe database, without an ORM?!
EdgeQL feature highlights:
Beautiful succinct schema definition language.
Another schema and query language to learn? But it really is worth it this time. EdgeQl schemas do not require specifying foreign key links (And Ids are auto-generated).
In EdgeQl:
1 type Person {2 property name -> str;3 link Car -> Car;4 }5 type Car {6 property exists -> bool;7 }In prisma
Managing links quickly becomes a maintenance burden.
1 model Person { 2 id Int @id @default(autoincrement()) 3 name String? 4 car Car 5 } 6 model Car { 7 id Int @id @default(autoincrement()) 8 exists Boolean? 9 ownerId Int10 owner Person @relation(fields: [ownerId], referenceds: [id])11 }In EdgeQL tasks like adding default values or expressing one-to-many, many-to-many, etc is simple. Just add multi in front of link.
Performant subqueries - always a single request
If you analyze prisma queries, they often split the query into multiple requests – which can become especially slow if your database is physically far from your client.
This is especially in serverless and/or edge architectures where your request can route around the globe in a single round trip.
For example, If your MySQL server exists in a google data center in us-central (i.e. chicago). However, Prisma connection pooling using the Prisma Data Proxy only exists in us-east (i.e virginia). So already, your request is being routed from the client, to virginia, to chicago, and back – for a single round trip. (this is further exagerated with edge functions which are distributed across the globe, although they can be restrictured to specific regions).
So if Prisma is breaking your query into multiple requests, then this already long round trip will be multipled.
Whereas with expresive EdgdeQL, even the most complex subqueries will all be compiled into a single query! So even if your requests are routing around the globe, your data will be returned in a single round trip. Additionally, there is no need for a separate serverless "data proxy" because connection pooling happens at the edgedb server itself! (more on this below)
Unmatched computed and aggregations - move logic from server into queries
While Prisma offers some relatively simple aggregation, counting, and grouping features – they are extremely limited compared to edgeql subqueries – AND will dramatically increase the amonunt of separate queries that Prisma produces.
And for many complex queries, they are simply not expressable via Prisma's query language.
So this often leads to over-fetching data and then filtering it on the server.
With EdgeDB computed values, you can calculate extremely complex expressions – and on filtered results only! (meaning the computed value is not needlessly calculated on objects that are not even returned). The computed value does not even need to be a property in the schema, is can exist in the query only.
This has dramatically simplified data fetching.
Edgdedb generators - typesafe interfaces, queries
And all of the complicated subqeury and computed values mentioned above can be written once and generated into type-safe query functions and typescript interfaces.
Edgedb UI is fantastic!
- A REPL to execute queries with auto-complete based on your schema
- A beautiful text/GRAPH visualizer of your schema! (no more ERDs)
The flaws
Edge function compaitble clients, and their limitations
The edgedb javasript client is around 175kb (39kb gzip). Not bad compared to Prisma 651kb (343kb gzip).
However, Prisma offers an edge client, which, after tree shaking, is only 17kb – and can operate in limited V8 runtime edge function environments. This is because the Prisma query engine is moved to the "data proxy" server (which also implements connection pooling).
EdgeDB does have a smaller HTTP client that can operate in edge funtions, however:
- As of V2.9 the ergonomic "query builder" (used in edgedb-js) does not work, nor do the generated query files. Instead, it requires passing edgeql queries as a string (variables are still allowed).
- Since HTTP can't sustain a connection like TCP, stateful edgedb features, like transactions, or direct DDL statements, are not allowed.
For most data fetching functions, I don't need stateful features anyway! (also transactions can be mimicked by stringing together queries in a with block or exeuting comma seprated EdgeQL scripts discord. I am mostly using edge functions for fast data fetching (without the relatively slow (300ms) nodejs cold start time). So if I do need transactions, then using a regular (non edge) nodejs cloud function would be well with the extra few milliseconds of nodejs instantiation time.
And writing queries as strings is not terrible with a good workflow, e.g. you can still run the query builder to type-check .edgeql files against your schema before copy and pasting as a string. And I'm sure this UX will be improved in future versions.
So the last big question:
Can edgedb scale in a serverless environment?
Many of EdgeDBs core pleasantries, such as linking, are build on top of PostgreSQL features. Similar to MySQL, PostgreSQL suffers from a connection limit. PostgreSQL's default limit is around 100 connections.
Well, with ephemeral serverless functions, 100 connections can be exhausted relatively quickly. One solution to this is "connection pooling" which attempts to re-use connections to the server for multiple requests. However, since serverless cloud functions are ephemeral, they are not a reliable way to reuse connection pools [vercel docs].
Prisma solves this by routing your serverless through another server that exists outside your application clients. This higher level server implements connection pooling among isolated serverless functions. However, this adds another dependency, and is limited by the connection pooling algorithm efficiency.
Another bigger solution to scaling MySQL's connection limit problem is "sharding", originally popularized by Vitess (developed to scale youtubes MySQL server), and now offered as a service by PlanetScale. PlanetScale essentially breaks the database into multiple MySQL servers, and efficiencly routes operations among them to avoid connection limits on any single server. This allows near infinite connections. However, Planetscale (which uses Vitess) explicitly states that their reliability comes from supporting the MySQL protocol only.
Can EdgeDB implement horizontal sharding? Well, EdgeDB is limited by the PostgreSQL protocol, which does not currently support native sharding. However, PostgreSQL does offer horizontal table "partitioning", which, paired with PostgreSQL "Foreign data wrappers" feature, can implement a type of sharding, though it's not "native sharding". PostgreSQL is working on native sharding, but it seems very early stage. EdgeDB developers are watching closely, and have tight release cycles following PostgreSQL. [discord1], [discord2] [discord3]
However, is horizontal sharding even necessary? (TLDR: only if you need more than "tens of thousands" of simultaneous connections!)
To my delight, EdgeDB does implement a connection pool, and it is attached to the EdgeDB server – so it works with serverless cloud function architectures – without any extra "data proxy" techniques! (clients can re-use connections too though, so this would be even more efficient in non-serverless architectures). Moreover, the connection pool algorithm is extremely efficient, using the "[uv loop]" package. EdgeDB developers state that even in serverless environments, a single edgedb server should be able to manage "tens of thousands" of connections!
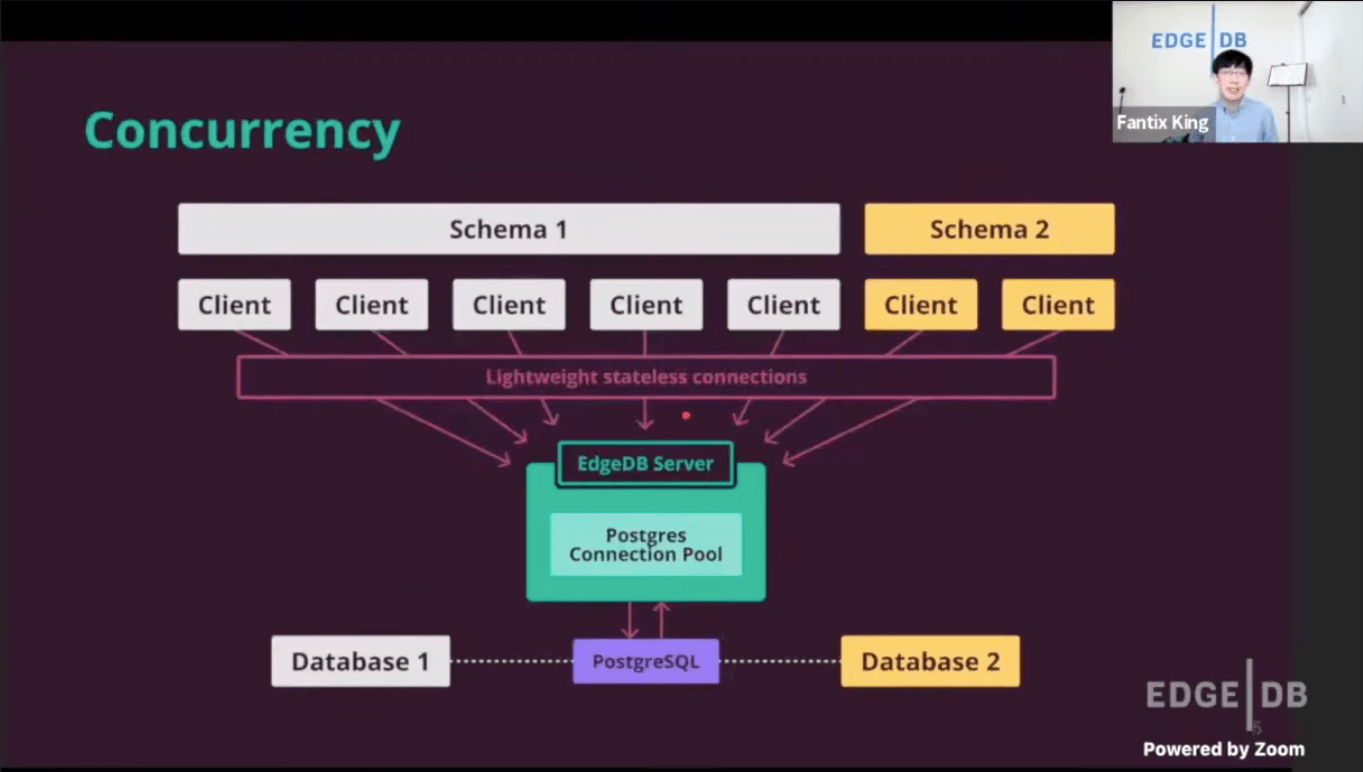
So for most apps, tens of thousands of connections are plenty. And if you are at a scale where it's not enough, you're likely paying for your own full-time servers, which would allow you to use the non-http clients, which would re-use connections – increasing this connection pool. And if this is not enough, then with time, EdgeDB will likely implement some horizontal scaling solutions as the PostgreSQL protocol evolves.
So in general, the one remaining hesitation I had about EdgeDB - scaling in serverless environments - is solved with an extremely efficient connection pool that exist at the EdgdeDB server.
Wow. What a time to be a developer. The only problem now is that it will take companies years to implement! But, maybe this cycle will be shorter than most given the influence of EdgeDB developers and their investors.
For more reading, I highly recommend edgeDB blog articles such as: Why ORMS are slow (and getting slower) and We can do better than sql. The EdgeDB quickstart is also fantastic.